Diecast
A Generator generates a site, maintaining a notion of input and output directories and bindings used to compile trees in the input directory to the output directory.
A Binding is a relation between a Pattern (representing a section of the input directory), the Compiler with which to build it, and its dependencies if any.
A Pattern is used to match against every file in the input directory. Default instances exist for simple strings (exact matches), regular expressions, and globs. Patterns can be conjoined, disjoined, and negated.
An Item represents a unit of compilation in Diecast and simply consists of a Path to the underlying file and an AnyMap representing arbitrary, type-checked metadata.
A Compiler is used to process an Item. Processing an item may involve performing side-effects based on an Item’s metadata or writing and updating metadata.
Parallelization
One of the goals is to have parallelized compilation. In order to do this I believe it’s necessary to determine the order in which Items must be built so that dependency constraints are satisfied. Further, for this ordering to be processable in a parallelized fashion it’s necessary to prevent dependents from being built before all of its dependencies are complete.
The ordering required is the topological ordering of a dependency graph. A dependency graph in this context is a directed acyclic graph (DAG) where an edge $a \to b$ means that $b$ depends on $a$, so that $a$ must be processed before $b$. A topological sort provides this ordering, so that all dependencies come before their dependents.
In the dependency graph below, $5$ and $6$ must be built before $4$, that is, $4$ depends on $5$ and $6$. One of the valid topological orderings is [8, 7, 2, 3, 0, 5, 1, 6, 4, 9, 11, 12, 10], which is the topological ordering resulting from a reverse post-order depth-first search.
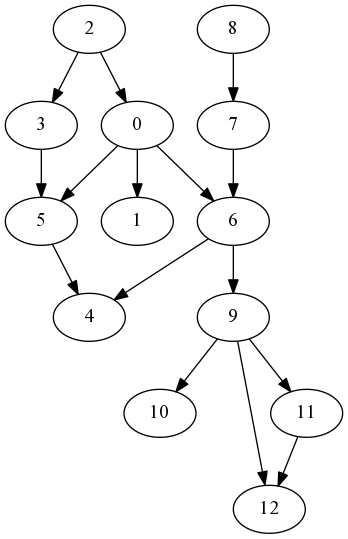
This ordering cannot be used directly as a work-stealing queue in a parallelized environment, however. Consider the first two items in the queue, 8 and 7. If one thread dequeues 8, another thread has no way of knowing that it shouldn’t dequeue 7 because 7 depends on 8. There has to be a way to hide unfulfilled items so that fulfilled items are not blocked by them, which would lead to something similar to head-of-line blocking, which would negate parallelization.
One solution to this problem is to give every Item a reference count corresponding to the number of dependencies it has. When a dependency finishes, every Item that depends on it should have its reference count decremented. An intelligent queue would then only serve those Items which have a reference count of 0.
A Job would contain an Item, along with its original topological ordering index and reference count. The original list of Items would be partition into unfulfilled (refcount > 0) and fulfilled (refcount = 0). Every fullfilled Job would be pushed onto the priority queue based on its original topological ordering index so that related jobs are kept closer together, i.e. compiled soon after their dependencies. This isn’t strictly necessary, and a regular FIFO queue can be used, including a channel.
It turns out that this approach has been described by others 1 2.
Ownership
A parallel approach would move each Job (and thus Item) into its assigned worker thread. This isn’t possible because then other Jobs in other worker threads would have no way of referencing the moved Item’s metadata.
It seems that there are two requirements:
- allow a worker thread to mutate a specific
Item - allow a worker thread to reference a specific
Item
I think that the RWLock is pretty relevant for this purpose.
A dual-mode reader-writer lock. The data can be accessed mutably or immutably, and immutably-accessing tasks may run concurrently.
One possible design is to move every Job from the work-stealing queue to its assigned worker thread. When the worker thread is done compiling the Item, it should then move it into a RWLocked collection that can be looked-up using a Pattern.
It seems particularly tricky to reconcile the following requirements:
- a graph which is used to obtain the initial topological order
- the
Itemneeds to be sent to the worker thread for processing - once processed it is sent back to the main thread where it needs to:
- decrement its dependents in the staging queue, which is done by querying the graph
- or be added back to a staging area when blocked by a
Barrier
A possible approach to begin with is the design of the general flow of the Items. The main thread would construct a work-stealing queue with the Items in topological order. Each TaskPool task clones the stealer and steals a Job and proceeds to processing it.
After processing the Job, it’s sent back through a channel to the main thread, which then determines what to do with it. If the Job is complete, the graph is queried for neighbors of the Item and decrements each of their reference counts which may mark them as ready and thus move them to the job queue. If the Job is incomplete, create a Barrier-tracking entry for it in the Generator if one doesn’t already exist, and if it’s the final Job to reach the Barrier then put all of the Jobs associated with the bind name back onto the job queue.
It seems that the principal problem is that the Job needs to be mutable within its worker task, but the Job also needs to be kept somehow in the graph and other structures in the Generator. One possible approach is to associate the original index with each Job, and have the graph and other structures operate purely based on the index.
Under this approach, the above steps would be done as:
- a graph is constructed using only the indices to output the topological order
- the
Jobs are created from theItems based on the topological order indices, storing the original index in a field in theJob - the
Jobis sent to the worker thread for processing - once processed, the
Jobis sent back to the main thread:- if the
Jobstatus isPaused, add it back to a staging area indexed by the original index - decrement its dependents in the staging queue based on the
Jobindex, which is done by querying the graph
- if the
Dependencies
An implicit dependency registration system would be more ergonomic and flexible, but I think it’s either infeasible or intractable in a parallel environment 3. It appears to me that it is necessary to explicitly state the dependencies of each binding up front in order to build the dependency graph and by extension the dependency-respecting ordering, which in turn is necessary for parallelization.
The API can be be made ergonomic despite requiring explicit dependency registration. Every binding could carry a friendly name which could then be referred to for purposes of dependency registration.
generator
.bind("posts",
"posts/*.md",
post_compiler,
None)
.create("post index",
"post-index.html",
post_index_compiler,
Some(["posts"]));
The Compiler would then be passed a map of name to Items, to prevent the Compiler from manually fetching Items it probably didn’t specify as dependencies.
fn compile(item: &mut Item, dependencies: Dependencies) {
let posts = dependencies["posts"].filter_map(|p| p.data.find::<Title>());
for Title(title) in posts {
// do something with `title`
}
}
Ordering Dependencies
How would this dependency system manage the scenario where a post contains links to the previous and next post? There is no way to specify a dependency on the next or previous post.
The simplest, but inflexible solution would be to maintain a notion of metadata (title, route, date, etc.) separate from all other data (post body, etc.). This way, metadata would be processed first and would be ready during regular compilation. The downside to this approach is that the same problem would arise for any other kind of data. However, if no alternatives seem feasible then this might be the only way forward.
Another approach would be to allow separate stages of compilation. Under this approach, “posts” would go through preliminary compilation, which might process the title and route, after which the second stage compilation would run which would allow the Compiler to refer to other posts. This would most naturally be facilitated by a Barrier Compiler, whose semantics would be much like a memory barrier, forcing all items in the binding to be compiled up until that point before proceeding.
let post_compiler =
CompilerChain::new()
// this reads the title
.link(ReadMetadata)
// force all posts to reach this point before proceeding
.link(Barrier)
// now we can refer to the title because we are guaranteed
// that it has been processed for every other post
.link(GetNextAndPreviousPosts);
Perhaps the Barrier should not be free-standing, and should instead be required to wrap the Compiler that has the ordering constraint? This would be much like the Mutex type in Rust.
let post_compiler =
CompilerChain::new()
.link(ReadMetadata)
.link(Barrier(GetNextAndPreviousPosts));
This wouldn’t really work well if there are multiple Compilers that require the Barrier.
let post_compiler =
CompilerChain::new()
.link(ReadMetadata)
.link(Barrier(GetNextPost))
.link(GetPreviousPost);
The above code could be reformulated with a CompilerChain.
let post_compiler =
CompilerChain::new()
.link(ReadMetadata)
.link(
Barrier(
CompilerChain::new()
.link(GetNextPost)
.link(GetPreviousPost)));
However, it would probably be best represented as an inherent method in the CompilerChain, which is the only place where a Barrier makes sense; all other Compilers are single Compilers.
let post_compiler =
CompilerChain::new()
.link(ReadMetadata)
.barrier()
.link(GetNextPost)
.link(GetPreviousPost);
It’s not possible to use an actual Barrier because there would be no way to know if what Jobs are currently on which tasks, or if they even all fit in the thread pool.
The implementation details of a system that would facilitate a Barrier Compiler seem complex. The worker must know when a Barrier is encountered, pause Compiler execution at that point, and put the Job back on the job queue. This might imply that a Job (or Compiler) has internal state about the compilation status, specifically whether it is Paused or Done, and if Paused, where it left off at.
Perhaps this should all only apply to the CompilerChain, in which case the chain should be represented as a queue which is dequeued as a Compiler is run, making the compilation state implicit: both completion (Paused or Done) and progress (which Compiler to continue on).
It could be that the worker thread invokes the compile method on the Item, and it could return an enum variant such as Done or Paused, which the worker would pattern match on to determine whether the Job needs to be re-inserted into the job queue.
Aside from pushing the Job back onto the job queue to continue compilation, the Item at that state needs to be pushed onto the Item store so that subsequent Compilers could reference the data that was built up until the point of the barrier. This would represent a frozen state, so I believe it has to be made a copy via clone.
match job.compile() {
Paused => {
store.insert(job.item.clone());
job_queue.push(job);
},
Done => /* decrement dependents, add to store */,
}
I’m not sure if the clone could be avoided, perhaps through some kind of copy-on-write semantics, perhaps the new Cow type? 3. It could also be that cloning doesn’t introduce too much overhead. At most there would be two copies of an Item at any given point: the master copy and the frozen one. This is not unlike the double buffer pattern used in much more performance-oriented games.
Special care needs to be taken if multiple Barriers are present in the same Compiler, as they could lead to race conditions. For example, consider Items A and B using the same Compiler C. If C contains two Barriers, then it could be that B’s second Barrier is encountered before A has even had a chance to encounter the first Barrier. In this case, by the time A encounters the first Barrier, B’s second Barrier would have overwritten the frozen state that A’s first barrier was protecting.
- B encounters first barrier, saves current state of B into read-only store
- B encounters second barrier, saves current state of B into read-only store
- A encounters first barrier
- subsequent
Compilerfor A expects B’s data at step #1, but step #2 has overwritten it
- subsequent
This problem would occur if jobs were re-enqueued onto the job queue as soon as a Barrier is encountered. To counter this, the Items shouldn’t be pushed back onto the job queue until all of Items affected by the Barrier have reached the Barrier.
This can be accomplished through the use of a counter which is decremented as Items reach the barrier. For this to work, the number of Items represented by a given Pattern must be known, so every Binding should be augmented with the number of Items that matched either explicitly as a separate field or implicitly if the Items are stored in a collection. The Generator should then contain a map of active Barriers mapping from the Binding name to a reference count denoting the number of Items yet to reach a barrier.
As soon as a Barrier is encountered by an Item, the Generator should check to see if an entry already exists in the collection of active Barriers:
- If an entry doesn’t exist yet, this is the first
Itemto encounter theBarrier. Inserted an entry with an initial reference count of$N - 1$where$N$is the number ofItems associated with thatBinding. - If an entry does exist, then it means that this is just another
Itemthat has reached the barrier. Decrement the reference count for the entry. If after this decrement the reference count reaches 0, then re-enqueue all of theItems associated with theBindingonto the job queue.
In either case, the Item should not trigger dependency resolution, as it’s not actually complete yet. This should be implicit since the Compiler wouldn’t have completed by then.
Caching
One of the goals of the caching implementation should be to keep each Compiler’s cache separate in order to prevent different Compilers from clobbering each other’s cache space.
Another goal should be to bypass as much work as possible. Given Compiler A and B where B depends on metadata inserted by A, if A avoids work because it determines that recompilation isn’t necessary, then B should also avoid work since it depends on A.
For this to be possible, it would be necessary to allow subsequent compilers to test the cache of previous compilers, to determine whether or not the work that is depended on has changed.
Granular caching could be achieved by having the Generator maintain an AnyMap mapping the Compiler type to the actual cache, a TypeMap mapping a pair of type and a descriptor string to the actual cached value.
Approach
The problem with the aforementioned ideas is that other compilers have to care about other compilers’ cache. I think the simplest approach here is to ignore caching altogether. Each compiler will instead have the option/choice of caching things if they should want to do so in some unique directory (?) in some standard cache directory.
Perhaps provide some sort of uniform API for hooking into caching functionality. It would cache things in a binary encoded manner? Or would it cache as simple as JSON? JSON would be portable, but binary encoded might be faster. Portability is probably not a huge concern with something as ephemeral as the cache. This API would also not have to worry about what directory to write things in? Though the directory will be available should a particular compiler want it.
Look into serde.
There should also be a way to handle in-memory caching? For use with the live command. Should probably have a way of pruning cruft when, e.g., a file is removed and its cached data is no longer needed.
Error Handling
There should be some facility for handling errors in compilers. Presumably each compiler should return a Result. Errors should probably consist of Box<Error> since I can’t think of any particular error that diecast might throw, instead it would be some underlying error, such as an io::Error.
Possible success return values would probably be Continue and Pause.
fn some_compiler(_item: &mut Item) {
// some work
Ok(Continue)
}
But what would it mean for a compiler to choose to pause? Should it be interpreted as a Barrier? So that all items being compiled with that compiler are put on a barrier?
fn barrier(_item: &mut Item) {
Ok(Pause)
}
The problem with implementing Compile for Compiler, and also a problem with allowing any compiler to Pause, is that the compiler needs to store its position to know where to resume from later.
The first problem is that the compile method has an immutable self. This can probably be circumvented by storing the position in a Cell.
The second problem could perhaps be solved by only giving a Pause significance within the context of a Compiler. That is, the compiler would run a compiler and if it returns paused it would itself return paused.
pub fn compile(&self, item: &mut Item) -> Result<Status, Box<Error>> {
let position = self.position.get();
for compiler in &self.chain[position ..] {
self.position.set(self.position.get() + 1);
match compiler.compile(item) {
Ok(Continue) => (),
Ok(Paused) => return Ok(Paused),
Err(e) => return Err(e),
}
}
Ok(Done)
}
What then should be returned when a compile chain is finished? It doesn’t make sense to allow Done because then any compiler could return Done to short-circuit evaluation?
Maybe we can get rid of a Compiler and only keep Chain.
Chain::new()
.link(inject_with)
.link(read)
.link(render_markdown)
.link(write)
.build();
This would allow us to pass compilers directly to Rule constructors:
Rule::matching(
"pages",
glob::Pattern::new("pages/*.md"),
|item: &mut Item| -> Result<Status, Box<Error>> {
// some work
Ok(Continue)
});
This would change the definition of Rule to be parameterized over the compiler.
pub struct Rule<C> where C: Compile {
pub name: &'static str,
pub kind: Kind,
pub compiler: C,
pub dependencies: Vec<&'static str>,
}
This would necessitate creating a Chain for a sequence of compilers. The Chain would handle behavior with respect to keeping track of the position of the sequence and propagating pauses and errors.
One consequence of this is that it would be possible to nest Chains, allowing for the pattern of packaging up common sequences of compilers into chains, such as Ring’s wrap-defaults.
fn setup() -> Chain {
Chain::new()
.link(read)
.link(parse_metadata)
.link(parse_toml)
.build();
}
Rule::matching(
"pages",
glob::Pattern::new("pages/*.md"),
Chain::new()
.link(setup())
.link(my_own_stuff)
.link(here)
.build());
Note that this would be different from a function that contains calls to each compiler in succession, unless the return value of each compiler is properly handled:
fn setup(item: &mut Item) -> Result<Status, Box<Error>> {
// return values are discarded!
read(item);
parse_metadata(item);
parse_toml(item);
}
A macro like try! should probably be created that early-returns on Ok(Paused) and Ok(Done), or should we co-opt Error to do this? So that we have some Error enum that contains variants for Paused and Done, and one for Other which contains a Box<Error>.
Then it should be possible to rewrite the Compile implementation for Chain as:
pub fn compile(&self, item: &mut Item) -> Result<Status, Box<Error>> {
let position = self.position.get();
for compiler in &self.chain[position ..] {
self.position.set(self.position.get() + 1);
compile!(compiler.compile(item));
}
Ok(Done)
}
However, the use of such a macro alone would not enable manual, sequential chaining of compilers in a function. If the parse_metadata compiler yielded Ok(Pause) it would correctly early-return from setup, but it would have no way of knowing where to resume.
If setup was called within a Chain, the chain would correctly resume compilation at the setup function, but the setup function would have no way of knowing where to resume compilation and so would re-run each of the functions.
fn setup(item: &mut Item) -> Result<Status, Box<Error>> {
// pause position discarded!
compile!(read(item));
compile!(parse_metadata(item));
compile!(parse_toml(item));
}
Honestly I don’t like allowing compilers to return Paused and Done. It doesn’t make much sense. Instead this should be contained within a Chain. In this case the return value should just be Result<(), Box<Error>>, since I can’t really think of what other values should be possible. It’s always awkward to type Ok(()) though, maybe type alias to Continue?
The problem is that Job needs to know what the return status of compilation is so it can know whether to re-enqueue the job or if it’s done. If we contain those return values to Chain only, then it requires a Chain to be used no matter what. I guess those are the two options:
- any compiler can use
PauseandContinueso thatChainisn’t mandatory Chainis mandatory
Should we be wrapping compilers in an Arc? If not then Compile would need a Clone bound. Better yet, why not wrap them in an Arc within the evaluator, to then be sent off to the thread pool? This would relax the requirements on individual compilers and would remove the need for the Compiler + Chain split.
EDIT: This makes it difficult for Chain to track internal state. This seems to break at the seams of the special casing of Chain.
Perhaps the position paused at should be encoded in the Pause variant as a stack with which to retrace the steps:
pub fn compile(&self, item: &mut Item) -> Result<Status, Box<Error>> {
// would need some way to resume from position
for (position, compiler)
in self.chain[position ..].iter().enumerate() {
match compiler.compile(item) {
Ok(Continue) => (),
Ok(Pause(mut stack)) => {
stack.push(position);
return Ok(Pause(stack));
},
Err(e) => return Err(e),
}
}
Ok(Continue)
}
It makes pausing from a “leaf” position slightly less ergonomic, such as from a barrier function:
fn barrier(_item: &mut Item) {
Ok(Pause(Vec::new()))
}
Alternatively, a Pause variant can be used at leaf positions, and they’re converted to Paused(stack) variants by Chain?
Updated: Compilers now return Result<(), Box<Error>>. Actual error handling is still not implemented because a thread pool that handles errors needs to be implemented.
Barrier Reform
Barriers currently require all items in the binding to pass through the barrier. This presents a problem in conditional compilation. The barrier will deadlock because it’ll be waiting for all items in the binding to reach the barrier, even though the barrier is only performed for items that satisfied the condition.
Chain::new()
.link(compiler::read)
.link(
compiler::only_if(
publishable,
Chain::new()
.link(compiler::print)
.barrier() // <-- deadlock!
.link(compiler::write)));
The most preferable solution would be one that completely removes the concept of pausing from the Site type as it currently presents a special casing/handling of the Chain compiler, which is contrary to the impression it gives, that it’s something that anyone can implement.
There needs to be a way to narrow the scope, perhaps a way of defining “sub-bindings.” One example would be for only_if to perform a barrier at its beginning in order to ensure registration of each item that satisfied the condition. Subsequent barriers would then be based on the immediate parent binding.
The problem with this approach is that currently the Site is what does the book-keeping for barriers. However, these book-keeping structures only refer to the binding, so theoretically they can be stored some place else? But where? It wouldn’t make sense to store them on an Item itself, unless it were a reference to the structure that’s actually stored some place else (the Site?).
UPDATE: This is wrong. The book-keeping structure actually stores the Item itself, which would need to be revised since we can’t move out of a &mut Item. Perhaps store the Job.id instead?
paused: BTreeMap<&'static str, Vec<Job>>,
Perhaps a barriers structure would be kept in the Site and a reference to it would be stored on each Item? Or could it be created once and cloned into each Item? It would be created by the Chain itself and would be stored as a stack, as with ChainPosition.
struct Chain {
chain: Vec<Link>,
// clone this into each `Item` in its compile fn,
// if the compiler doesn't already contain it
barriers: Arc<Mutex<BTreeMap<&'static str, Vec<JobId>>>>,
}
The Item would contain a stack of barriers. Each Chain compile fn would push the latest barriers layer and would not pop it until the Chain finished?
// insert the barriers key if it doesn't already exist
let barriers = item.data.entry::<Barriers>().get()
.unwrap_or_else(|v| {
let barriers: Vec<Arc<Mutex<BTreeMap<&'static str, Vec<JobId>>>>> =
Vec::new(Arc::new(Mutex::new(BTreeMap::new())));
v.insert(barriers);
});
// insert one if there isn't one already for this level
let barrier = if barriers.is_empty() {
let bar = Arc::new(Mutex::new(BTreeMap::new()));
barriers.push(bar.clone());
bar
// if there is, get it
} else {
barriers.pop().unwrap();
};
An alternative, easier approach would be to maintain a concept of a “target barrier count.” Since by definition only one barrier could be active at any one moment, we will maintain a count of the amount of triggers required. By default this target count would be the total length of the binding, which would also be stored in a BindCount anymap entry, to facilitate resetting. When an only_if is triggered, it would perform a barrier to count the number of items that satisfy the condition, then after the barrier use that count to update the target barrier count. This way, subsequent barriers would only perform on this subset of items.
Side note: Instead of maintaining a blind count, should we maintain a set of Job ids? This would facilitate the handling of errors in the rare event that a job slips through that shouldn’t have?
One implementation possibility would be to maintain a stack of target barrier counts, so that a nested chain would pop the count off when it has finished, thereby reinstating the previous chain’s target barrier count. This would facilitate the nesting of only_if, for example.
The Site type would then consult the top of this target barrier count (using teh last method)? This seems to be complicated because a barrier itself is required to perform this change:
- chain (could be inside an
only_if) - item adds its jobid to the new target barrier count
- barrier
- as an item reaches this preliminary barrier, it would be checking the previous target barrier count (TBC)
- swap target barrier counts. much like a double buffer in graphics rendering, swap the target barrier count with the new one if it hasn’t been done already (if
!=)
Some double-buffering like this would be required to avoid corrupting the target barrier count as the barrier itself is being performed to update the target barrier count.
Unresolved Questions
-
Maybe make it possible to set the sorting to use for
Items in aBinding. Consider the scenario of adding next and previous post links. To get the next and previous posts, the entire posts would need to be sorted in chronological order. If theItems aren’t already sorted in chronological order, then this sorting would occur for every singleItembeing compiled in theBinding.Alternatively, if it were possible to store
Binding-level data, then a separateCompilerdirectly following theBarriercould sort theItems in chronological order once, then construct a map ofItems to tuples of previous and nextItems. SubsequentCompilers could then refer to thisBinding-level data. (This doesn’t really make sense, since thisCompilerwould run for everyItem. There would then need to be some way to preprocess aBinding, i.e. aBindingCompiler.) -
Should it be possible to store
Binding-level data? Would this require anRWLockof theBinding? It would also have to be passed to everyCompiler?- this seems to be possible with
compiler::inject_with
- this seems to be possible with
-
How will drafts be handled?
- conditional compilation
compiler::only_if(publishable, some_compiler) -
How will tags work?
- rule that depends on all items that contribute to the tags
- groups all items by tag
- injects some sort of tag info structure
- rule that builds tag index based on tag info structure (or merge this step into previous compiler?)
-
How will pagination work?
Rust Gripes
- lack of polymorphic mutability
- can’t iterate over one field while calling a function that takes a
&mut self- hacks:
- wrap field in
RefCell - wrap field in
Option - swap field out and then back with
mem::replace. playpen
- wrap field in
- hacks:
-
Stanley Tzen, Brandon Lloyd, John D. Owens. A GPU Task-Parallel Model with Dependency Resolution. Page 3, Section 5. ↩︎
-
Getting parallel items in dependency resolution on the Computer Science StackExchange ↩︎
-
This requires further investigation. ↩︎