Computer Architecture
Metrics
Moore’s Law states that every 18-24 months we get twice the number of transistors onto the same chip area. Essentially, processor speed doubles, energy/operation halves, and memory capacity doubles. The memory wall thus refers to the fact that latency only improves by 1.1x every 2 years, whereas CPU performance and memory capacity double every two years.
Dynamic power is consumed when there is activity on the circuit, whereas static power is consumed when the system is powered on but idle. The active power is:
where $C$ is the capacitance (proportional to chip area), $V$ is the power supply voltage, $f$ is the frequency, and $\alpha$ is the activity factor (e.g. what percent of the processor transistors are actually active).
The fabrication yield can be computed as:
The two different ways in which the benefits of Moore’s Law can be reaped are lower cost: a smaller chip that does the same thing as the larger, previous generation chip, or increased speed for the same cost: new chip with the same area that is faster and more capable for the same cost as the previous generation chip.
The Iron Law for measuring CPU time is computed as:
Amdahl’s Law measures the speedup when only a fraction of the program was enhanced. The enhanced fraction refers to a percentage of the original execution time that is affected by the enhancement. The implication of Amdahl’s Law is to focus on optimizing the common case.
Lhadma’s Law cautions that in pursuit of optimizing the common case, the uncommon case shouldn’t be slowed down too much.
Diminishing returns with respect to Amdahl’s Law refers to the fact that continuing to optimize a specific part of the execution eventually provides less and less gains in speedup, because the optimized portion grows smaller and smaller, accounting for less and less of execution time. Intuitively, it can be considered that the “low hanging fruit” of optimizations will be gone after a while, making it harder to optimize. The practical implication of this is that after optimizing a portion of the execution, one must re-evaluate which portion is now dominant.
Pipelining
Pipeline stalls can happen due to data dependencies. For example, an instruction reads a register but another instruction farther down the pipeline is set to write to that register. The read instruction would obtain an outdated value if it weren’t stalled until after the write completed.
Pipeline flushes may be necessary due to jump instructions. By the time the pipeline recognizes that it’s a jump instruction, the instructions that follow it are already inside the pipeline behind the jump instruction’s stage. Since those instructions which follow the jump instruction aren’t actually going to be executed, they need to be flushed out of the pipeline.
The longer a pipeline is, the higher the cost of branch misprediction, because it means that more instructions will have been loaded into the pipeline which need to be flushed.
Dependencies
A control dependency is when an instruction depends on a branch, such that the pipeline cannot know whether to load those instructions until it determines the result of the branch. These can be eliminated with branch prediction.
A data dependency is when an instruction depends on data computed by a previous instruction.
A read-after-write data dependency (RAW) is when an instruction has a data dependency because it tries to read a value after it was written by a previous instruction. Instructions with RAW dependencies must stall. Forwarding isn’t possible for RAW dependencies because it would imply time travel, i.e. sending the written value to the read that occurred in the past.
A write-after-write data dependency (WAW) is when the order of the writes must be preserved. For example, if adding two registers and storing the result in register A, then subtracting two registers and storing the result in register A, the final value of register A should be the subtraction result.
A write-after-read data dependency (WAR) is when a write must occur until after a register was read by a previous instruction.
Read-after-write dependencies are also known as true dependencies because the read truly depends on the write having occurred. True dependencies can be mitigated by out-of-order execution.
Write-after-read and write-after-write dependencies are also known as false dependencies, or name dependencies, because the only reason that the dependency exists is because the same register is being used for two different results. For example, in write-after-write, two different instructions may write to the same register.
Register renaming is a way to eliminate false/name dependencies. It establishes two kinds of registers. Architectural registers are ones that the programmer/compiler uses, and physical registers are the actual locations the values go to. Register renaming rewrites the program to use physical registers, and uses a Register Allocation Table (RAT) to map architectural registers to physical registers.
The RAT begins with some predefined architecture-to-physical register mappings. Each instruction’s architecture register operands are rewritten to physical registers based on those mappings. Every time an instruction writes to an architectural register, that target architectural register is rewritten into a new/different physical register, and the entry for that architectural register is updated in the RAT.
A structural dependency comes about when there isn’t enough hardware to perform an operation in the same cycle. For example, if the current instruction requires an adder but all adders are currently being used, it has to wait.
A pipeline hazard is when a dependency results in incorrect execution. It’s important to note that a dependency in a pipeline doesn’t automatically result in a pipeline hazard.
In order to resolve hazards caused by control dependencies, it’s necessary to flush the dependent instructions.
In order to resolve hazards caused by data dependencies, it’s necessary to either stall the dependent instructions or forward the correct values to them.
The reason that instructions are loaded into a pipeline before even knowing if a branch will take place is that in the event that the branch is not taken, no stalls are necessary.
Branch Prediction
The only basis on which a branch predictor may predict is the current instruction’s address, i.e. the program counter (PC). In particular, the branch predictor must determine if the current PC is a taken branch, and if so, what the target PC is.
Given the choice between always predicting that a branch isn’t taken, and refusing to predict at all by waiting until the branch predicate is computed, it’s much better to always predict that the branch isn’t taken. This way, in the worst case, it will not be any more costly than waiting until the predicate is computed, and in the best case it will be significantly faster.
The predict not-taken branch predictor works by always predicting that the branch is taken, which is accomplished by simply implementing the PC as usual.
Since a branch predictor can only base its decision on the instruction PC, without knowing if the current instruction even is a branch (since the instruction hasn’t been decoded), whether it’s taken, or its offset, the way that a branch predictor can improve its predictions is by remembering the previous results for that same PC.
A branch table buffer (BTB) is a table that maps the current PC to the predicted target PC. If it was a misprediction, the target PC is updated for that current PC. In order to keep the BTB small and the lookup fast, the table is indexed by some of the least significant bits of the PC, since those are more likely to differ from one instruction to the next.
A branch history table (BHT) is a table that maps the current PC to whether the branch was taken (1) or not (0).
The BTB works by indexing into the BHT to determine if the branch is taken. If the branch is taken, index into the BTB to determine the target PC. Otherwise if the branch isn’t taken, simply increment the PC as usual. On a misprediction, the BTB and BHT are both updated. If it mispredicted that the branch was taken and it wasn’t, only the BHT is updated to reflect that the branch isn’t taken.
When indexing the BTB and BHT, the least significant bits are used except for the first few bits that represent the instruction alignment boundaries, because those bits will always be zero. For example, on a 32-bit architecture the instructions are word aligned, which means that all instructions are on 4-byte boundaries, which also means that all instruction addresses are divisible by 4, which means that all instruction addresses end in 00.
The 2-Bit Predictor (2BP) (aka 2-Bit Counter (2BC)) works by maintaining a counter that counts from 0 (0b00, not taken) to 3 (0b11, taken). If the counter is 1 (0b01) or 2 (0b10), the prediction remains the same as the previous, unless it’s a misprediction. The first bit can be interpreted as a prediction bit, specifying whether the branch is taken or not. The second bit can be interpreted as a hysteresis (conviction) bit, specifying how “sure” it is of the prediction bit’s value.
| Counter | Meaning |
|---|---|
| 0b00 | strong not-taken |
| 0b01 | weak not-taken |
| 0b10 | weak taken |
| 0b11 | strong taken |
The advantage of the 2-Bit Predictor is that a single anomaly will not completely change the prediction. For example, given a small loop, finishing the loop will cause a misprediction, but it won’t change the prediction value to not-taken because the majority of the time it is taken. Instead, it would only change if the misprediction happens again.
The preferred state of a 2-Bit Predictor is one of the weak states, 2 or 3, since there’s a one-time misprediction cost in the worst case. If it started on a strong state, such as 0 or 4, then there would need to be two mispredictions to update the prediction.
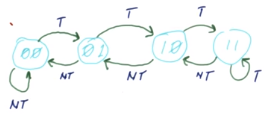
The pathological case of initializing a 2-Bit Predictor with a weak state is that if it alternates between taking a branch and not taking the branch, then each misprediction will only flip between the weak states, causing a misprediction every time. If it had started on a strong state, it would only move to a weak state on a misprediction, which would mean that the prediction would be correct half of the time.
More generally, every branch predictor has a sequence where it will mispredict 100% of the time.
A history-based predictor works by keeping track of the last $N$ branch outcomes to determine the next one.
A 1-Bit History BHT works by storing the branch outcome bit along with two 2-Bit Counters. On any given prediction, the current branch outcome bit is used to determine which 2-Bit Counter to use for the prediction. On a misprediction, the outcome bit is updated to reflect the outcome. Regardless of the outcome, the chosen 2-Bit Counter is updated based on that outcome.

An entry in the BHT of a 2-Bit History Predictor contains 2 bits of history and 4 x 2-Bit Counters (one for each history configuration).
An N-Bit History Predictor must store for each entry in the BHT, $N$ history bits and $2^N$ 2-Bit Counters, one for each configuration. The 2-Bit Counter that is used for any particular prediction is determined by the history bits.
An N-Bit History Predictor can accurately predict all branch prediction patterns of length $\le N + 1$. An N-Bit History Predictor requires, per entry;
The PShare Predictor works by storing a private history for each branch and sharing 2-Bit Counters. The history bits are stored in a Pattern History Table (PHT). Each entry is XORed with the PC bits to index into the BHT to obtain the shared 2-Bit Counters. When the 2-Bit Counter is updated, the new history is mapped to this updated counter.
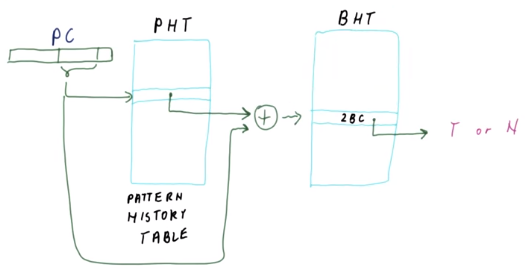
The GShare Predictor works similarly to the PShare Predictor, except that there is a global history. This is useful for correlated branches. For example, the following branches are correlated in the sense that if one branch is taken, the other is not:
if (shape == square)
// ...
if (shape != square)
// ...
The Tournament Predictor works by leveraging multiple predictors, such as GShare and PShare, and using a Meta-Predictor Table, which stores entries specifying which of the other predictors is more likely to be correct.
The Hierarchical Predictor works similarly to the Tournament Predictor, except that where the Tournament Predictor uses two good predictors and pays a considerable cost for each, a Hierarchical Predictor uses one “good” predictor and one “OK” predictor.
Whereas in a Tournament Predictor both branches are updated on each branch outcome, in a Hierarchical Predictor, the “OK” predictor is updated on each branch outcome, but the “good” predictor is only updated if the “OK” predictor was not correct.
A real-world Hierarchical Predictor in the Pentium M processors works by maintaining a hierarchy of predictors: 2-Bit Counters, Local, and Global predictors. If the 2-Bit Counter mispredicts, that entry is added to the Local predictor, and likewise Local to Global. The Local and Global predictors maintain a tag array indicating whether or not that PC is covered by that predictor.
A Return Address Stack (RAS) predictor is for predicting the target of a function return. A BTB alone would always remember the previous call’s return, which may not be the same call and so would be incorrect. An RAS predictor works by maintaining a stack. On each function call, the return address is pushed. On each function return, the stack is popped. An RAS predictor is necessary aside/separate from the regular program call stack because it’s necessary for fast predictions. When the RAS predictor stack is full, pushes wrap around. Like branch prediction, a RAS predictor needs to be usable even before the instruction is determined to be a return instruction (RET), which is accomplished by using a simple predictor or pre-decoding the instruction.
Predication
Branch Predication refers to executing the instructions on both directions/sides of a branch, so that only half of the work is wasted and discarded. This is primarily useful when it ends up being much faster than the branch misprediction overhead.
if-conversion works by removing an if condition where both branches are similar, so that instead the work of both branches is done and the correct result is chosen based on the original condition.
// BEFORE
if ( cond) {
x = arr[i];
y = y + 1;
} else {
x = arr[j];
y = y - 1;
}
// AFTER
x1 = arr[i];
x2 = arr[i];
y1 = y + 1;
y2 = y - 1;
x = cond ? x1 : x2;
y = cond ? y1 : y2;
During an if-conversion, the result of the correct branch must be chosen, but doing it by using a branch would defeat the purpose of the if-conversion:
x = cond ? x1 : x2;
Instead a conditional move instruction can be used. A conditional move instruction performs a move only if the condition is true. On x86, this refers to the cmovz, cmovnz, cmovgt, etc. family of functions.
r3 = cond
r1 = x1
r2 = x2
movn x, r1, r3 ;; use r1 if cond is != 0 (true)
movz x, r2, r3 ;; use r2 if cond is == 0 (false)
Full branch predication refers to adding condition bits to every instruction which specifies whether the instruction actually carries out its operation. Some instructions are used to establish the predicates and the subsequent instructions can be predicated with them so that they only carry out their operation if that predicate holds.
; if r1 == 0 { p1 = 1, p2 = 0 } else { p1 = 0, p2 = 1 }
mp.eqz p1, p2, r1
(p2) add1 r2, r2, 1 ;; only add if p2 == 1
(p1) add1 r3, r3, 1 ;; only add if p1 == 1
Instruction Level Parallelism (ILP) refers to what the Instructions Per Cycle (IPC) would be on an ideal processor which can execute an entire instruction in 1 cycle, and can execute any number of instructions in the same cycle while obeying true dependencies. ILP is a property of the program, not the processor, since ILP concerns an ideal processor which doesn’t exist.
The ILP of a program is determined by renaming registers and “executing” through the code. For example, given:
add p10, p2, p3
xor p6, p7, p8
mul p5, p8, p9
add p4, p8, p9
sub p11, p10, p5 ;; true dep on: add's p10 and mul's p5
The ILP of the above program is:
2 cycles are necessary because the first 4 instructions can be done in the same cycle in the ideal processor defined by ILP, but the final instruction would occur in the next cycle due to the true dependencies present in the code.
When determining ILP, structural dependencies are not considered since they concern hardware limitations, but ILP presupposes an ideal processor, that is, every instruction that can possibly execute in the same cycle will execute in the same cycle without having to wait on some resource (e.g. all adders are being used).
When determining ILP, control dependencies are not considered since ILP assumes a perfect, same-cycle branch prediction, so that branches still execute but have no impact on delaying further instructions.
ILP is constrained by the issue-width and the order of execution. If narrow-issue and in-order, ILP is limited by narrow-issue. If wide-issue and in-order, ILP is limited by in-order because it prevents saturation of the issue-width. If wide-issue and out-of-order, ILP is maximized because out-of-order can continue to find instructions to saturate the wide-issue, regardless of their order.
Out-of-Order Execution
Tomasulo’s Algorithm is an instruction scheduling algorithm for out-of-order execution. It determines which instructions have inputs ready so that they could begin in the next cycle, whereas the rest still have to wait for their inputs to be produced. This also includes register renaming.
As instructions are fetched from the instruction queue they are placed in a reservation station, where they wait for their parameters to become ready. Existing registers are placed into the instructions that depend on them in the reservation station.
When an instruction’s result is computed, it is broadcast on a bus and ends up in the register file for the appropriate destination register, and/or in a reservation station’s instruction’s operands if needed.
Data resulting from a load (from memory) has an output to broadcast on the bus (sent to the register file or dependent reservation stations). Store (in memory) operations have an input from the load data and computed value bus, so that storing data from registers into memory can be accomplished as soon as the register values become available.
When an instruction is issued it means that it’s taken off of the instruction queue and sent to the store unit and reservation station.
When an instruction in a reservation station becomes ready, it is dispatched, which means it is sent to the compute unit.
When an instruction has computed its result and is ready to be broadcast, it performs a write result or broadcast. In particular, the reservation station producing the result as well as the result itself is broadcast.
On each cycle, different instructions will be in any one of the following phases:
- issue: fetch instruction from instruction queue, determine dependencies from RAT
- capture: update dependencies with latest results
- dispatch: send instruction for execution
- write result (broadcast): send result to reservation stations, write to register file, update RAT
During the issue phase, the next instruction in program order (so that register renaming works correctly) is taken from the instruction queue. Then the input registers are identified and their source determined—whether already in the register file or produced by an instruction that hasn’t yet finished executing—by looking in the RAT. Then a free reservation station of the correct kind (adder, multiplier, etc.) is found. If all reservation stations are taken, nothing is issued this cycle. The instruction is placed into the free reservation station. The instruction’s destination register is tagged so that the result is placed there and future instructions that require the register know which instruction produces it.
The Register Alias Table (RAT) is used so that fetched instructions can identify the reservation stations that they depend on, and so that they can specify that all future instructions that require its destination register should wait for its reservation station (i.e. wait for it to complete). If an entry is empty, it signals to other instructions that they should simply read the value from the actual physical register in the register file because the result has already been computed.
During the dispatch phase, the reservation station of the just-completed instruction is freed. All reservation stations that depend on the just-completed instruction’s result have the result inserted in the corresponding operand(s). Those instructions that become ready are dispatched to the execution unit. If more than one instruction is ready, we choose the instruction to dispatch based on some policy, such as oldest first, random, or most-dependencies first (difficult to implement/costly).
During the write result (broadcast) phase, the reservation station’s tag and result are broadcast on the bus. The result is written to the register file by indexing the RAT with the tag to determine the actual register. The RAT is updated so that the entry that contained the tag is cleared, which signals that the register file should be read instead. Finally, the reservation station with that tag is freed.
When more than one instruction finishes in the same cycle and they need to be broadcast, some heuristic is used to quickly determine which one goes first. Usually a priority is given that is inversely proportional to the speed of the unit. For example, if the multiplier is slower than the divide, the multiplier is given a higher priority. This is because they will have been executing for a longer time, so it’s more likely that they have more dependencies on them by now.
A stale result can occur because another instruction clobbered/overwrote the same entry in the RAT. If a stale result is broadcast, the reservation station is updated with the result as usual. However, the RAT is not updated because no further instructions will ever use that result. This is because for the result to be stale, it means that another instruction overwrote its entry in the RAT, and that only occurred because there is a newer instruction that is producing the value for that same register.
In Tomasulo’s Algorithm, loads and stores occur in-order.
Reorder Buffer
Exceptions are a problem in Tomasulo’s Algorithm because after returning from the exception handler to the excepting instruction, the instructions that follow might have already executed out-of-order. This may clobber/corrupt the operands of the excepting instruction, which would result in an incorrect result on resumption.
Branch mispredictions are a problem in Tomasulo’s Algorithm because out-of-order execution can execute instructions following a branch instruction even if there ended up being a misprediction, in which case those instructions shouldn’t have executed.
A phantom exception is an exception that triggered despite a branch misprediction, in which case the excepting instruction should never have executed to begin with.
To ensure proper out-of-order execution, values should be deposited to registers in-order. This way, if it turns out that an instruction shouldn’t have executed (i.e. due to exceptions or branch mispredictions), the instruction’s destination register will not have been overwritten.
A reorder buffer (ROB) is a buffer that remembers the program order and keeps the result of instructions until they are safe to write. A typical entry contains the value produced by the instruction, a done bit specifying whether the value has been set, and the register to write to.
Two pointers into a reorder buffer (ROB) are maintained. The commit pointer points to the next instruction to be completed, and the issue pointer points to where new instructions should be written. The commit pointer trails after the issue pointer, and both wrap around when needed.
A ROB entry is allocated for a new instruction when the new instruction is issued, same as when a reservation station is acquired for the instruction.
When using an ROB, the RAT should point to the ROB entry instead of the register.
During the commit phase of Tomasulo’s Algorithm with an ROB, for all instructions from the commit pointer onward that have results ready, the result is written into the target register and the RAT is updated to point to that target register.
On a branch misprediction in Tomasulo’s Algorithm with an ROB, the branch’s entry in the ROB is marked as a misprediction and the issue pointer is moved to the same location as the commit pointer, as if aborting those instructions. Each RAT entry is made to point to the corresponding register instead of the ROB, the reservation stations are freed, and the ALUs are emptied without broadcasting the results.
On an exception in Tomasulo’s Algorithm with an ROB, the exception is treated as any other result and the actual handling of the exception is delayed until the excepting instruction commits.
When committing an instruction’s result, the result is written to the corresponding register, regardless of what the RAT says. However, if the corresponding RAT entry points to the ROB entry, then the RAT entry must be cleared so that further instructions consult the register file instead of the ROB.
A unified reservation station is one where, instead of having separate reservation stations for different execution units (add, mul, etc.) there is one big one to maximize utilization. However, the dispatch and broadcast logic complexity increases.
A superscalar processor is one that simultaneously fetches, decodes, issues, dispatches, broadcasts, and commits more than one instruction per cycle each.
CPU manufacturer terminology differs from issue, dispatch, and commit:
- issue: issue, allocate, dispatch
- dispatch: dispatch, execute, issue
- commit: commit, complete, retire, graduate
The instruction execution process is:
- fetch
- decode
- issue
- execute
- write result (broadcast)
- commit
Steps 1-3 (fetch, decode, issue) are done in-order to ensure that discovered dependencies respect the original program order. Steps 4-5 (execute, broadcast) are done out-of-order to enable execution in the order of the data dependencies. Step 6 (commit) is done in-order to give the appearance that instructions are executed in-order.
In a Tomasulo-like scheduling policy, memory writes occur at the commit phase, to ensure that the instruction really will be executed.
Load-Store Queue
A Load-Store Queue (LSQ) is used to supply values from previous stores to future loads. Each entry contains a load/store bit, memory address, value to be stored in memory or value that was loaded from memory, and a completion bit. Load and store instructions get LSQ entries instead of a reservation station.
When an load entry is added to a Load-Store Queue, the LSQ is checked to see if any previous store entry in the queue matches that address. If so, a store-to-load forwarding is performed to copy the value from that entry without ever having gone to memory.
If a new load entry causes a check of previous store entries for an address match, but one of those store entries hasn’t computed its address yet, then the load goes ahead as if no store entry matched, i.e. it access memory. If the store entry’s address is eventually computed to be the same as the future load, the load will have read a stale value, since it was meant to have read the data written by the store. For this reason, when stores compute their addresses they check subsequent loads to see if they match the address, in which case they are re-triggered.
As soon as a load instruction receives data, it is broadcast to dependent instructions in reservation stations.
Data from a store instruction is sent to memory during the commit phase.
A load/store instruction is committed by freeing the ROB and LSQ entries for it. For stores, the data is also send to memory.
Load/store instructions are executed in address computation and value production, and a store instruction in particular can do those in any order.
Tree height reduction is a way for the compiler to help with ILP by exploiting associativity in order to break up larger computations into smaller independent computations, thereby reducing overall dependencies, hence reducing the dependency tree height.
;; input
r8 = r2 + r3 + r4 + r5
;; before
add r8, r2, r3
add r8, r8, r4
add r8, r8, r5
r8 = (r2 + r3) + (r4 + r5)
;; after
add r8, r2, r3
add r7, r4, r5
add r8, r8, r7
Instruction scheduling by the compiler aims to reduce stalls by reordering (usually independent) instructions to maximize ILP.
Loop unrolling increases the benefits of instruction scheduling because it increases the window/context of the loop contents, which gives access to more instructions that can be reordered via instruction scheduling.
Loop unrolling decreases the number of instructions that are executed, essentially minimizing the branching overhead.
Loop unrolling once refers to modifying a loop so that it does one extra iteration’s-worth of work per iteration, i.e. 2x the normal amount of work. Unrolling twice would mean that that the loop does two extra iteration’s-worth of work per iteration, i.e. 3x the normal amount of work.
for (size_t i = 1000; i != 0; i--)
a[i] = a[i] + s;
// unrolled once
for (size_t i = 1000; i != 0; i = i - 2) {
a[i] = a[i] + s;
a[i - 1] = a[i - 1] + s;
}
Function call inlining eliminates call/return overhead and allows for better instruction scheduling because the function’s instructions are inline.
Both loop unrolling and function call inlining increase code size.
A Very Long Instruction Word (VLIW) processor is one that executes one large instruction which does the same work as $N$ “normal” instructions. Examples include Itanium and DSP processors. The advantages are that the compiler does the hard work (via instruction scheduling), so the hardware can be simpler and more energy efficient because there is less to do per instruction (no need to detect dependencies), and they work well on loops and “regular” code. The disadvantages are that the latencies of instructions aren’t always the same, and the compiler can’t predict them (e.g. on a cache miss), most applications are irregular with lots of decisions and branches, and finally there is a large increase in code size due to no-op insertion due to dependencies.
Caches
The locality principle states that things that will happen soon are likely to be close to things that just happened. Temporal locality means that if a memory address was accessed recently, it’s likely to be accessed again soon. Spatial locality means that if a memory address was accessed recently, an address close to it is likely to be accessed as well.
A cache’s Average Memory Access Time (AMAT) is the access time to memory as seen by the processor. It’s computed as:
A cache’s miss time is the overall time it takes to have a cache miss. It’s computed as:
A CPU’s Level 1 (L1) cache is the cache that directly services read/write requests from the processor. It’s usually 16-64KB in size, large enough to get about 90% hit rate, and small enough for the hit time to be about 1-3 cycles.
A cache block or line size is how many bytes are stored in each cache entry. The cache block size should be at least as large as the largest single memory access, but large enough to exploit spatial locality, so that more data is brought in on each access. Typically block sizes on L1 caches are not much bigger than 32-128 bytes because it’s a balance between exploiting spatial locality while minimizing the possibility that space goes wasted when programs don’t exhibit spatial locality.
If the cache block size is smaller than the largest single memory access, then each memory access will incur multiple cache look-ups for each single memory access.
If the cache block size is not much larger than the largest single memory access, then spatial locality will not be exploited because the local data will not fit in the entry.
If the cache block size is very large but the program does not exhibit much spatial locality, then the space is wasted since the data is never used.
In caches, blocks start at block-aligned addresses. For example, for 64 B blocks, block 1 would be 0-63, block 2 would be 64-127, and so on.
On a given memory access, the region of memory that is brought into the cache is the region that contains the data and is block-aligned, that is, the same size as the cache block.
A cache line is a slot into which a cache block fits. To differentiate, the cache block is the actual data fetched from memory which is inserted into a slot called a cache line.
The block number is the block that corresponds to the memory address that is being accessed. It’s determined by dividing the memory address by the block size.
The block offset is the offset into a particular block that corresponds to a particular memory address. This is necessary because each block may contain more than one memory address’ data. It’s computed as the remainder of the memory address divided by the block size.
The number of bits used in a cache block offset is determined by the size capacity in bytes (if byte-addressable) of a cache line, or $\log_2 (\text {cache line byte size})$.
The block size should be a power of 2 because it simplifies the process of determining the appropriate block for a particular memory address, which is done by dividing by the block size. Dividing by $2^k$ is just a right-shift by $k$ bits, i.e. discarding the lower $k$ bits determines the block number. This is much simpler and faster than dividing by a non-power of 2.
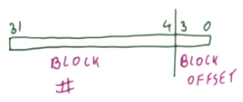
For example, given a block size of $2^4$ = 16 bytes and a 32-bit address, the block offset is the least significant (lower) 4 bits and the block number is the most significant 28 bits.
// address / 2^4
block_number = address >> 4;
// address % 2^4
block_offset = address & 0xFF; // i.e. 0b1111
For a cache to determine if a block is actually in the cache, it keeps a tag for each cache block. The tag of a given address usually consists of at least one bit from the block number component—even the entire block number can be the tag. On a given memory access, the cache checks to see if the tag for that address is present in the cache, in which case the corresponding cache block contains the data.
In order to prevent garbage data from being used after booting a CPU, the cache keeps a valid bit for each cache line which specifies whether the tag and data are valid. Once data is read from memory, the valid bit is enabled. This way, a hit is successful if the address’ tag is present and the valid bit is on.
A cache size is typically expressed as how much data it can contain, but it is actually larger due to cache book-keeping overhead such as storing the tag, valid and dirty bits, LRU counters, etc.
A multi-level cache (cache hierarchy) can help to reduce the miss penalty because additional cache levels are still much faster than accessing memory.
The Last Level Cache (LLC) is the cache with no more caches beneath it, so that misses go directly to memory. For example, in a single-level cache, the L1 cache is the LLC.
A cache’s local hit rate is the hit rate that the cache actually observes for accesses to this particular cache, dependent on the hit rate of the caches above it.
A cache’s local miss rate is simply the complement of the local hit rate:
A cache’s global miss rate is the number of misses in this cache divided by all memory accesses that the CPU makes:
A cache’s global hit rate is simply the complement of the global miss rate:
Misses per 1000 Instructions (MPKI) is a metric of how often the cache hits, which tries to capture the behavior of non-L1 caches:
Cache inclusion means that if a block is in the L1 cache, then it also has to be in the L2 cache.
Cache exclusion means that if a block is in the L1 cache, then it cannot also be in the L2 cache.
If cache inclusion nor cache exclusion is enforced, then if a block is in the L1 cache, it may or may not be in the L2 cache. To maintain the inclusion property, each cache line in L2 needs an inclusion bit which is set if the block is also in L1, so that blocks in L2 that are also in L1 are never replaced.
The benefits of enforcing the inclusion property are that it ensures that an L1 write-back is an L2 hit, or that an L1 write-through actually happens in L2 and not in memory, and it also speeds up coherence since only the L2 needs to be probed: if it’s not in L2, it won’t be in L1, so the L1 doesn’t need to be probed.
Direct-Mapped Cache
A direct-mapped cache is one where, for a given cache block, there is exactly one cache line where it may go.
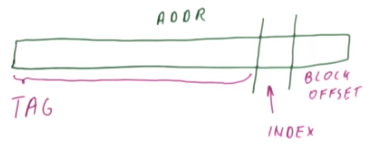
A direct-mapped cache can be thought of as a special instance of a set-associative cache where there is a set for each cache line, i.e. a 1-way set associative cache. This way the index bits are still used to determine the cache line.
In a direct-mapped cache, a cache block’s cache line is determined by using some index bits, which are taken from above the block offset component. The number of index bits used is determined by the number of lines in the cache, in particular, $\log_2 (\text {total lines})$. The tag comprises the rest of the bits, essentially identifying which of all possible blocks that can go in that cache line is actually present.
The advantage of a direct-mapped cache is that there is only one place to look-up for a block, making it fast, cheap, and energy-efficient. However, since a given block can only go in one place, it increases contention/conflicts for each cache line, which increases the miss rate.
The cache block offset granularity is in bytes (on x86), or the smallest addressable unit of memory.
Set-Associative Cache
A set-associative cache is one where, for a given cache block, there are $N$ cache lines where it may go. Cache lines are grouped into sets. The number of sets there are is equal to the number of cache lines divided by $N$. A cache is n-way set-associative when a particular block can be in one of $N$ lines within a unique set. That is, each block maps to a unique set, but may choose among the lines within that set.
The number of index bits used in an n-way set-associative cache is $\log_2 (\text {number of sets})$.
The associativity of a cache refers to how many cache lines are assigned to each set. More cache lines per set means the cache is more associative.
Fully-Associative Cache
A fully associative cache is one where any cache block can be in any cache line, so each tag must be checked in order to see if a block is present.
A fully associative cache can be thought of as a special instance of a set-associative cache where there is one set containing all of the cache lines. This means that there are no index bits, because $\log_2(\text {number of sets = 1}) = 0$.
An address in a fully associative cache doesn’t require an index component because the tag alone identifies the correct line, since any block can go in any line in a fully associative cache.
Cache Replacement
Cache line replacement is necessary when a set is full or there was a cache miss and we need to put a new block in the set.
Possible cache replacement policies include random, Round-Robin (FIFO), and Least Recently Used (LRU).
Least Recently Used
LRU is a good policy because it exploits temporal locality. It works by maintaining an LRU counter that is set to a different count for each cache line in the set. A count of 0 is considered to be the Least Recently Used.
When a block needs to be replaced, the least recently used block of count 0 is replaced, its cache line’s LRU counter is set to the max (i.e. marked MRU), and all other LRU counters are decremented.
When an LRU block is re-accessed, its LRU counter is set to the max (i.e. marked MRU) and all other LRU counters are decremented.
When the MRU block is re-accessed, there is no change.
When a block that’s not the LRU or MRU is accessed, its LRU counter is set to the max (i.e. marked MRU) and all other LRU counters with a count greater than the previous count of this block are decremented.
For an n-way set-associative cache, an LRU implementation requires $N$ counters (one for each cache line) of bit size $\log_2 (n)$, for each set.
A counter-based LRU cache implementation requires all $N$ counters in the set to be updated on each access, even on cache hits.
Not Most Recently Used
Not Most Recently Used (NMRU) is an approximation of LRU which works by tracking which block has been used most recently, then picking a random block aside from that one, so that the just-used block isn’t replaced. This entails keeping one MRU pointer per set. For example, in a 2-way set-associative cache, there would be a 1-bit pointer per set to specify which of the two entries in the set is the MRU. In general, a pointer of size $\log_2 (N)$ is required per set.
NMRU is much cheaper than true LRU because each set only requires one pointer to the MRU, compared to true LRU where each entry in each set requires its own counter.
The main disadvantage of NMRU is that it only keeps track of the MRU and chooses any of the other blocks for replacement, which may not be the actual LRU.
Pseudo-Least Recently Used
The Pseudo-LRU (PLRU) replacement policy works by keeping one bit per line in each set. All bits are set to 0, and they are then set to 1 whenever their block is accessed. On replacement, any of the blocks with a 0 bit is eligible for replacement. This essentially means that all of the recently accessed blocks will have a 1 bit.
When the final 0 bit block is replaced and its bit is set to 1, all of the other block’s bits (which should be 1, since this is the last 0 bit block) are set to 0.
The performance of PLRU is between true LRU and NMRU. When there’s only one 0 bit block left, it’s essentially like LRU. When there’s only one 1 bit block, it’s essentially NMRU. And when there are more than one but not all 1 bit blocks, it’s in between.
Cache Write Policies
A cache write policy’s allocate policy concerns whether a block that was written to should be brought into the cache.
A write-allocate cache is one where, when a memory block is written to, it’s also brought into the cache.
A no-write-allocate cache is one where, when a memory block is written to, it’s not brought into the cache.
A write-through cache is one where, when a cache block is written to, the memory is updated immediately.
A write-back cache is one where, when a cache block is written to, the memory isn’t updated until that cache block is replaced. A dirty bit is used to determine if the block was modified since it was placed in the cache, which means that memory has to be updated with its data.
Most modern processors are write-back in order to exploit write-locality and eliminate the cost of sending to memory many times. Most modern processors are write-allocate in order to exploit locality between reads and writes, that is, if we write to something, we’re also likely to read it.
Write-allocate and write-back work together because write-allocate will bring data into memory on a write-miss in order to continue to benefit from write-back (writing only to cache block until it is replaced).
Cache Misses
The three main causes of cache misses are the “3C’s” (three C’s): compulsory misses, capacity misses, and conflict misses.
A compulsory miss is a miss incurred when the block is accessed for the first time. It’s compulsory because it has to happen in order to bring the block into the cache for the first time. In other words, it would be a miss even if the cache were of infinite size.
A capacity miss is a miss on a block that was previously evicted because of limited cache size. In other words, it would be a miss even in a fully-associative cache of the same size, that is, even if there had been many lines to choose from.
A conflict miss is one that occurs due to a conflict within a set, because the block was previously replaced due to limited associativity (not enough lines per set). It would not have been a miss in a fully-associative cache of the same size.
Prefetching
Prefetching refers to predicting which blocks will be accessed soon and bringing them into the cache ahead of time, before they’re actually accessed. Prefetching could eliminate cache misses, but mispredictions could lead to cache pollution, which leads to other misses because useful data was replaced.
Cache pollution refers to bringing unused junk data into the cache, potentially replacing data that was actually being used.
Prefetch instructions are instructions which the compiler or programmer can use to request prefetches.
The correct amount of data to prefetch via prefetch instructions is difficult to get right because it’s largely dependent on hardware, and it’s possible to prefetch too little or too much data.
If the amount of data prefetched is too small, it might arrive long after it’s actually needed, negating the purpose of prefetching.
If the amount of data prefetched is too large, the data may be evicted by the time it’s actually needed.
Furthermore, if the CPU gets faster but the memory doesn’t (as is often the case), the time at which the program needs the data will change, necessitating a change in the amount of data to prefetch.
Hardware prefetching is prefetching done by the hardware (e.g. CPU or cache), which requires no changes to the program.
A stream buffer prefetcher is a hardware prefetcher that is sequential in nature. It tries to predict if some sequence of blocks following the one that was just accessed might be accessed next, in which case it tries to prefetch several blocks in advanced.
A stride prefetcher is a hardware prefetcher that tries to determine if memory accesses are at a fixed distance from each other, in which case it prefetches data at subsequent fixed distances 1.
A correlating prefetcher is a hardware prefetcher that tries to detect patterns of memory access sequences, so that when it detects a repeat of a pattern, it prefetches the remaining sequence up to some number. This is good for linked lists which aren’t sequential in memory nor at fixed strides. Traversing the linked list in the same manner another time would yield a prefetch.
Non-Blocking Caches
A non-blocking cache is one that doesn’t block until each operation is finished, unlike a blocking cache.
In a non-blocking cache, a hit-under-miss is when the cache can continue to serve the cache hits while the cache is waiting on a miss.
In a non-blocking cache, a miss-under-miss is when multiple requests to memory can be made even while a cache miss is already underway. This is an example of memory-level parallelism and requires memory hardware support.
For a cache to support miss-under-miss functionality, it requires Miss Status Handling Registers (MSHRs), which remember what was requested from memory (i.e. information about ongoing misses).
On a miss, the MSHRs are checked for a match to determine if it’s a new or existing miss. If it’s a new miss, an MSHR is allocated and it remembers which instruction in the processor to wake up. This is called a miss.
If it’s an existing miss which is under way, and the data hasn’t come back yet, the instruction is added to the existing MSHR for that miss. This is called a half-miss.
When the data finally comes back from memory, all instructions in the MSHR are woken up, then the MSHR is released.
The more MSHRs there are, the more memory-level parallelism that can be leveraged because multiple misses can be serviced at the same time.
Virtual Memory
Virtual memory is split up into virtual pages because it decreases the size of the page table compared to if each byte in virtual memory mapped to a byte in physical memory.
A virtual address can be split up into two components: the virtual page number and the page offset.
The number of bits used for the virtual page number is dependent on the number of entries in the page table:
The remaining bits are used for the page offset.
A flat page table is one where there is a page table entry for every page number, that is, 1 entry per page in the entire virtual address space, even those regions unused by the program. Each entry contains the frame number and the access bits. The size of a flat page table is:
The problem with flat page tables is that they take up space even for virtual address space that isn’t being used by a process. Since a page table exists for each process, this can become prohibitively expensive for much larger address spaces.
A multi-level page table is able to save a lot of space by adding levels of indirection and only allocating the regions of virtual address space that are actually used.
A virtual address is broken down into the virtual page number and page offset as usual, but the page number is broken down further into outer and inner indices into the multi-level page table.
Larger page sizes lead to smaller page tables but increased internal fragmentation. Smaller page sizes lead to larger page tables.
On each memory access, the processor needs to:
- compute the virtual address
- compute its page number
- compute the physical address of the page table entry, given the current page table address and the virtual page number
- read the page table entry
- compute the physical address
- access the cache (or memory if cache miss)
On a multi-level page table, for each level, the processor needs to:
- compute the physical address of the page table entry, given the current page table address and the virtual page number
- read the page table entry
- compute the physical address
Without a translation look-aside buffer (TLB), virtual-to-physical address translation is expensive because on multi-level page tables, a mere virtual-to-physical address translation incurs multiple memory accesses because the page tables reside in memory. All this before the actual physical address can be read, which itself is yet another memory access.
A TLB is necessary instead of just using the CPU cache for caching translations because the cache is very big and is mostly for data, whereas a single virtual-to-physical address translation covers an entire page-worth of data, so a specialized cache like the TLB can be much smaller. Further, the general CPU cache would cache each intermediate result from a multi-level page table translation, whereas the TLB only needs to store the translation result.
When there’s a TLB miss, the actual translation is made manually using the page tables, and the final result is inserted into the TLB.
Software TLB-miss handling is when it is the operating system’s responsibility to handle a TLB miss, including performing the translation manually. This also means that the operating system can use any representation for the page table, since it’s the only one that is using it.
Hardware TLB-miss handling is when the processor automatically reads page tables and updates the TLB on a miss. This is much faster than software TLB miss handling, and it requires that the page tables be in a form that the hardware expects.
A TLB is typically fully or highly associative. Since it’s already very small and thus fast, it’s not necessary to make it directly-mapped as that would increase the miss rate.
The TLB size should be large enough to cover more memory than the cache, so that the TLB hits at least as often as the cache. For example, 64-512 entries. If more space is required, making the a single TLB larger would make it slower, so instead a two-level TLB is used, where L1 is small and fast and L2 is slightly slower but much larger, yet still faster than manually performing the translation.
The three main methods of improving cache performance are those that reduce the AMAT: reducing the hit time, miss rate, and miss penalty.
Reducing the hit time of a cache can be accomplished by:
- reducing the cache size (though bad for miss rate)
- reducing the cache associativity (though bad for miss rate)
- overlapping cache hits with each other
- overlapping cache hits with TLB hits
- optimizing lookup for the common case
- maintaining replacement state more quickly
Cache hits can be overlapped/coalesced by pipelining the cache.
Hit time is affected by the TLB hit latency because the TLB has to be accessed before the cache can be accessed, in order to get the physical address used to search the cache. The overall cache hit latency is the TLB hit latency plus the cache hit latency:
A Physically Indexed, Physically Tagged (PIPT) cache (aka Physically Accessed Cache, aka Physical Cache) is one that is accessed using a physical address.
A Virtually Accessed cache is one that is accessed using the virtual address. On a cache miss, the TLB is checked for the physical address to bring that data into the cache. Realistically, the TLB still needs to be checked to get the address’ permission bits. The advantage is that the hit time is now just the cache hit time, since there’s no need to look-up the TLB first. However, the TLB still has to be accessed to retrieve for example the permission bits, and the cache must be flushed on each context switch since virtual addresses are specific to a single process.
A Virtually Indexed, Physically Tagged cache is one that is indexed by the virtual address’ index bits, while the tag bits come from the physical address. The virtual address’ tag bits are used to get the frame number from the TLB. The cache block’s tag is then compared to the physical address to determine a hit or miss. The cache and TLB look-ups are done in parallel.
The advantages of a virtually indexed, physically tagged cache are that, since the cache and TLB look-ups are done in parallel, and the TLB is usually small and fast, the total latency is usually just the cache hit time. Unlike a virtually indexed, virtually tagged cache, the cache doesn’t need to be flushed on each context switch because although the cache is indexed by the virtual address’ index bits, a hit is determined by the physical address’ tag bits. Aliasing is not a problem if the cache is small enough.
The disadvantage of a virtually indexed, physically tagged cache is that aliasing can be a problem, i.e. when multiple virtual addresses map to the same physical address, but they would each get their own separate entries, so a write to one may not be seen by the others. This requires additional handling which might negate the aforementioned performance gains.
Aliasing can be avoided. Since a virtual address’ page offset is the same as the physical address’ frame offset—since pages and frames are the same size—if the cache’s index bits are taken from the same region as the page offset bits, then aliasing will not occur, because any number of virtual addresses that map to the same physical address will contain the same page offset, after all, it’s the virtual page number that differs, not the offset into the page/frame. This means that any aliased virtual addresses will map to the same cache line.
The cache size must be restricted by the number of page offset bits and the cache block offset bits. Specifically, the number of index bits must be:
For example, given a 4 KB page and 32 B cache blocks, there will be a 12-bit page offset since $\log_2 (4096) = 12$ and a 5-bit block offset since $\log_2 (32) = 5$, resulting in a 7-bit index since 12 - 5 = 7, which amounts to $2^7 = 128$ sets.
The only way to increase the cache size while preventing aliasing in a virtually indexed, physically tagged cache, given that the maximum number of index bits are already being used, is to increase the associativity of the cache. For example, going from a 2-way set-associative cache to a 4-way set-associative cache. However, this increases latency since it introduces more blocks that must be checked for a hit.
Way prediction refers to predicting which line is most likely to hit based on the index bits, instead of checking all of the cache lines in the set. If there is a misprediction, then all other lines are checked as usual.
Loop Interchange
Loop interchange is when a compiler modifies a nested loop in order to better exploit spacial locality. This is only possible if the compiler can prove that the rearrangement is equivalent to the original code.
For example, if a loop traverses a 2D array in column-major order (first element of the first row, first element of the second row, etc.), loop interchange would change it to row-major order.
Before:
for (i = 0; i < 10; i++)
for (j = 0; j < 5; j++)
a[j][i] = 0;
After:
for (j = 0; j < 5; j++)
for (i = 0; i < 10; i++)
a[j][i] = 0;
Memory
Static Random Access Memory (SRAM) is memory that retains its data (hence static) while power is supplied. On the other hand, Dynamic Random Access Memory (DRAM) is memory that will lose the data (hence dynamic) if it’s not refreshed.
SRAM is more expensive than DRAM because it requires several transistors per bit, meaning a lot less data per unit area than DRAM. SRAM is also typically faster than DRAM.
DRAM is cheaper than SRAM because it only requires one transistor per bit, meaning a lot more data per unit area than SRAM. DRAM is also typically slower than SRAM.
Since a DRAM bit’s capacitor slowly leaks through the transistor, it’s necessary to periodically read out the bit and write it back at full voltage.
A destructive read refers to the fact that reading the value drains the capacitor, so the bit loses its value, which means it needs to be written back.
Hard Disks
In a hard disk, all platters rotate at the same speed because they’re attached to the same spindle, which moves them all at the same time.
There are surfaces on both sides of each hard disk platter. Data is read from the magnetic surfaces by a magnetic head attached to an arm. Each surface’s head is attached to the head assembly. The head assembly moves the heads in unison, i.e. they’re all in the same position, reading the same track.
A cylinder is the collection of tracks accessible from the current position of each of the heads, as determined by the head assembly.
A track is the circle of data accessible from the current head position. There are many concentric tracks on each platter surface.
Data is stored on a track in individual chunks (or frames) called sectors. At the beginning of the sector is a recognizable bit pattern called a preamble which marks the beginning of the sector, followed by the actual data, and ending with checksums and other metadata. Sectors are the smallest unit of data that can be accessed.
A hard disk finds a particular sector on a track by first moving the head to the track, then reading the track until it finds a sector, which includes the sector’s position and number, so that the head knows how far to skip to get to the target.
Hard disk capacity can be computed as:
Seek time is the amount of time it takes to move the head assembly to the correct cylinder so that one of the heads is above the track that contains the data.
Rotational latency is the amount of time it takes for the start of the target sector to be under the head.
A data read refers to reading until the end of the sector seen by the head. It depends on how fast the disk is spinning, and how many sectors there are per track. For example, if there are 10 sectors on a track, a data read of one sector will be a tenth of the rotation.
The controller time is the time it takes for the disk to complete its overhead, for example verifying the checksum.
The I/O bus time is the time it takes for the data to arrive at memory once it has been read by the disk.
Fault Tolerance
A fault is when something inside the system deviates from specified behavior.
An error is when the actual behavior in the system deviates from the specific behavior.
A failure is when the system deviates from specified behavior.
A latent error is an error that is eventually activated.
An activated fault becomes an effective error.
For example, a function that works fine except for a specific input is an example of a fault, or latent error.
When a function yields an incorrect result for some input and it’s called with that input, that is an example of an error, specifically an effective error, due to an activated fault.
If a scheduling system calls a function that returns an incorrect input for some input, which leads to a scheduling mistake, that is an example of a failure, because the system (the scheduling system) deviated from the system behavior.
Dual-mode redundancy is a way to detect errors by comparing the results of 2 modules.
Triple-mode redundancy is a way of detecting and recovering from errors by having modules vote on the correct result.
Parity is an error detection method which stores an extra bit, where the bit is the XOR of all of the data bits. If one bit flip or an odd number of bit flips occurs, the parity bit will be incorrect and an error would be detected.
Fault tolerance for memory and storage can be accomplished by error detection and correction codes, such as parity.
An Error Correction Code (ECC) is a way of both detecting and correcting data.
Single Error Correction, Double Error Correction (SECDED) is an ECC method which can detect and fix one bit flip, or detect (but not fix) two bit flips.
Redundant Array of Independent Disks
Redundant Array of Independent Disks (RAID) are a variety of methods of having several disks act as one disk. Each disk still detects errors using error codes.
The goals of RAID are better performance and normal read/write accomplishment despite bad sectors and entire disk failures.
RAID 0
Since each individual disk can only access one track at a time before going to the next one, accessing a sequence of tracks is slowed by having to do them one after another.
RAID 0 “stripes” the data so that track 0 is on one disk, track 1 is on another, track 2 is on another, and so on, so that they could each be accessed simultaneously compared to if they were each on the same disk.
A stripe is a collection of tracks that can be accessed simultaneously across the disk array.
RAID 0 multiplies the data throughput by the number of disks in the array. For example, a three-disk array multiplies throughput by 3.
RAID 0 improves performance but reduces reliability.
RAID 0 degrades reliability since the failure of any one of the disks in the array causes the data to be lost. It has the effect of dividing the Mean Time to Failure (MTTF) by the number of disks in the array.
The storage capacity of a RAID 0 array is the total storage of all disks in the array.
RAID 1
RAID 1 works by mirroring the data so that the same data is written to all disks in the array. Data can then be read from any of the disks in the array.
The write time is essentially the same as having just one disk, since all disks perform the write at the same time.
RAID 1 multiplies the data throughput by the number of disks in the array, since the data to read can be split among all of the disks since they each contain copies.
RAID 1 increases reliability since copies of the data exists on each disk in the array. Error correction also increases because the error can be detected by the disk as usual and fixed by reading from another disk.
The storage capacity of a RAID 1 array is the minimum storage capacity of the disks. For example if they’re all 200 GB but one is 100 GB, then the capacity of the RAID 1 array is 100 GB.
RAID 4
RAID 4 works via block-interleaved parity. Of the $N$ disks, $N - 1$ contain striped data as in RAID 0, while the last disk has parity blocks. The tracks of each stripe are XORed to compute the corresponding parity block. If one disk fails, the remaining disks and the parity block can be XORed to reconstruct the data of the failed disk.
RAID 4 multiplies the data read throughput by $N - 1$, i.e. ignoring the parity disk.
The data write throughput of RAID 4 is half the throughput of one disk, because it requires two accesses for every write. This is because the parity disk has to be accessed to read the old value and the new value has to be written back.
RAID 5
RAID 5 works by distributed block-interleaved parity. Unlike RAID 4, the parity blocks are spread among all disks. For each stripe, the disk that stores that stripe’s parity is the next disk from the one that did so previously, and all other disks store the stripe of the data.
RAID 5 multiplies data read throughput by the number of disks in the array.
Four accesses are necessary per write, specifically:
- read data block
- read parity
- write data block
- write parity
However, each of those accesses is distributed among all of the disks, so that the write throughput is:
RAID 5 has the same reliability as RAID 4: it fails if more than one disk fails, but if only one disk fails, it can be reconstructed from the remaining data.
The storage capacity of a RAID 5 array is:
Essentially one disk’s worth of storage is spent on parity.
RAID 6
RAID 6 works similar to RAID 5 but stores two parity blocks per stripe: one parity block and another check-block, so that it can tolerate 2 failed disks. If one disk fails, parity is used to reconstruct it. If two disks fail, equations are solved to reconstruct them.
The advantage of RAID 6 over RAID 5 is that it can handle two disk failures, for when it’s likely that the second disk fails before the first disk is replaced. However, RAID 6 has twice the overhead, and more write overhead, since there are two parity blocks that have to be updated each time, meaning 6 accesses per write versus the 4 of RAID 5.
Cache Coherence
Flynn’s Taxonomy on Parallel Machines is a taxonomy based on the number of instruction streams and the number of data streams.
| Instruction Streams | Data Streams | |
|---|---|---|
| Single Instruction, Single Data (SISD) | 1 | 1 |
| Single Instruction, Multiple data (SIMD) | 1 | > 1 |
| Multiple Instruction, Single Data (MISD) | > 1 | 1 |
| Multiple Instruction, Multiple Data (MIMD) | > 1 | > 1 |
A uniform access, aka symmetric multiprocessor, aka centralized shared memory multiprocessor, is one where all cores can access the same main memory with uniform memory access (UMA) time, because the main memory is at the same distance from each core.
The problem with centralized main memory is that there is higher memory bandwidth contention due to misses from all cores, which creates a bottleneck on the cores doing their work.
Distributed memory is when only one core can access a memory slice and the others can’t, so that each core’s access time to each memory slice is non-uniform.
With simultaneous multi-threading (SMT), the processor is able to mix instructions from different threads in the same cycle.
In SMT, if the cached data of two threads don’t have much in common and don’t both fit in the cache at the same time, code thrashing may occur because each thread will keep cache missing and bringing in data, potentially kicking out the other thread’s data, and the other thread may do the same. In this scenario, the performance of SMT can be—and usually is—significantly worse than processing the threads one at a time.
A private cache is a cache that is specific to a core, i.e. a per-core cache.
A shared memory system is incoherent when the same memory location has different values from the perspectives of different cores.
Caches are coherent if:
- read
$R$from address$X$on core$C_1$returns the value written by the most recent write$W$to$X$on$C_1$if no other core has written to$X$between$W$and$R$. - if
$C_1$writes to$X$and$C_2$reads after some time, and there are no other writes in-between,$C_2$’s read returns the value from$C_1$’s write - writes to the same location are serialized: they must be seen to occur in the same order on all cores
Write-update coherence is when writes are broadcast to update other caches.
Write-invalidate coherence is when writes invalidate other copies.
Snooping coherence is when writes are broadcast on a shared bus, so that caches “snoops” on the writes.
Directory coherence is when each block is assigned an ordering point in order to maintain a consistent write order.
Write-update coherence can be optimized with respect to the number of memory writes by giving a dirty bit an additional meaning. Caches snoop on the bus for reads as well, and when a read is detected for data that it has modified (i.e. is dirty), it serves that data over the bus, avoiding a slower memory access.
If a previously served dirty block in cache $A$ is modified/dirtied by another cache $B$, cache $B$’s write is broadcast over the bus and is picked up by $A$, but now $A$ unsets the dirty bit, essentially relinquishing ownership of the block to cache $B$.
Write-update coherence can be optimized with respect to the number of bus writes by adding a share bit to each block, denoting whether the block is shared with other caches (i.e. other caches contain copies of that block).
If cache $A$ has a block and it snoops that another cache $B$ reads or writes to that block, cache $A$ sets the block’s shared bit to 1 and alters the bus so that when $B$ receives the data, it knows that the block is shared and sets its shared bit to 1 as well.
When a write hit occurs, the write is only broadcast over the bus if the shared bit is 1, since that would mean that other caches would need to be aware of that write in order to remain coherent.
Write-invalidate snooping coherence works such that, when cache $A$ reads a block and cache $B$ writes to that block, cache $A$ snoops the read on the bus and invalidates the block by setting its valid bit to 0.
Most modern processors use write-invalidate coherence because it better handles situations where a thread moves to another core. With write-update, the thread’s cache data in the previous core’s cache will continue to be updated even though it’s no longer needed there.
Given a memory access pattern of a burst of writes to one address, write-invalidate is the better cache coherence policy because the first write will invalidate the other copies only once, whereas write-update would send the update over the bus on each write.
Given a memory access pattern of writes to different words in the same block, write-invalidate is the better cache coherence policy because it invalidates all other copies only once on the first write, whereas write-update will send the update over the bus for each word write.
Given a memory access pattern of producer-consumer on separate cores, write-update is the better cache coherence policy because the producer sends updates which enables consumer reads to be cache hits. On the other hand, write-invalidate will cause the producer to invalidate the consumer’s copy each time it writes.
Given the situation of a thread moving from one core to another, write-invalidate is the better cache coherence policy because the old core’s cache blocks will be invalidated only once the first time they’re updated. On the other hand, write-update will continue to update the old core’s cache on each write to the blocks even though they’re no longer being used, until those blocks are replaced.
A coherence miss is a cache miss caused by cache coherence. For example:
- core 1 reads a block
- core 2 writes to the same block
- core 1 attempts to read the block again, but it has been invalidated, so it has a cache miss
A true sharing coherence miss is when different cores access the same data.
A false sharing coherence miss is when different cores access different data, but within the same block. It occurs because cache coherence operates at the cache block level.
As the number of cores increases, coherence traffic also increases because each core will have invalidations and misses.
MSI Coherence
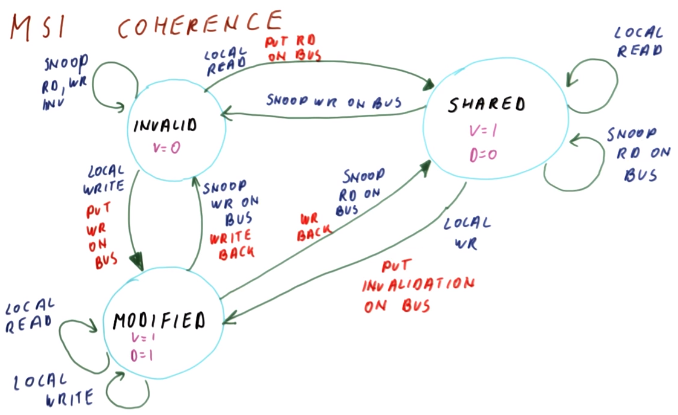
MSI Coherence is named after the 3 states that it allows a cache block to be in: Modified, Shared, and Invalid.
If a block in shared state is read, it remains in shared state. This is considered a local read.
If a block in modified state is written or read, it remains in modified state, because we can be sure that any other copies have been invalidated. This is considered a local read/write.
A block in modified state has its valid and dirty bits on.
A block in invalid state has a valid bit of 0, so that the value of the dirty bit doesn’t matter.
If a block in invalid state is written to, it transitions to the modified state while putting the write on the bus in order to invalidate all other copies.
If a block is in modified state and it snoops on the bus that another cache wrote to that block, it transitions to the invalid state (i.e. it becomes invalidated). This modified block is also write-back’ed so that the other cache that wrote to the block and thus invalidated this block gets this modified/dirty data.
If a block is in modified state and it snoops on the bus that another cache read that block, it transitions to the shared state, because the block copy is not the only one anymore. This modified block is also write-back’ed so that the other cache that read the block gets this modified/dirty data.
A block in shared state has a valid bit of 1 and dirty bit of 0.
If a processor places a read request of a block that is in the invalid state, the block transitions to the shared state. It also places the read request on the bus so that the data may be served by a block transitioning from the modified state to the shared state if there is any such block, or from memory if not.
If a block is in the shared state and snoops on the bus that another cache wrote to that block, it transitions to the invalid state.
If a block is in the shared state and is written to (local write), then the block transitions to the modified state. It also puts an invalidation on the bus.
A cache-to-cache transfer works as follows:
- core 1 has block
$B$in modified state - core 2 puts a read request for
$B$on the bus - core 1 has to provide the data since it contains local modifications not yet available in memory
An abort-and-retry cache-to-cache transfer works as follows:
- core 1 cancels core 2’s request (abort bus signal)
- core 1 can do a normal write-back to memory
- core 2 retries, getting the data from memory
The disadvantage of an abort-and-retry cache-to-cache transfer is that it incurs twice the memory latency: once for the write-back from core 1 and again for the read from core 2.
An intervention cache-to-cache transfer works as follows:
- core 1 snoops on the bus for the read request
- core 1 tells main memory that it will supply that data instead (known as an intervention signal) so that the memory shouldn’t respond
- core 1 responds with its local copy of the data
- main memory must pick up the data in order to update memory, since otherwise both blocks will be in the shared state (with dirty bit unset)
The disadvantage of an intervention cache-to-cache transfer is that it requires more complex hardware.
MOSI Coherence
Memory writes can be avoided on cache-to-cache transfers by introducing an owned state to the MSI coherence state machine, hence MOSI coherence.
Among all shared blocks in the shared state, one of the caches will be the owner, so that for that particular cache, the block is in the owned stated.
When another cache requests/reads the block, the owner can respond in order to avoid a memory read.
When the owner replaces the block, it’s in charge of write-back.
If a block is in the modified state and snoops a read, the data is provided and it transitions to the owned state, instead of transitioning to the shared state as in MSI coherence. The other read blocks do transition to the shared state. Unlike MSI, the data is not write-back’ed.
If a block is in the owned state and snoops a read, it provides the data.
If a block is in the owned state and it’s replaced by the cache, it must be write-back’ed.
With respect to thread-private data, even though the data is thread-private and so will never be shared with another core, it has to go through a sequence of transitions before it converges/arrives at the modified state, specifically:
- invalid state
- cache miss
- shared state
- invalidated
- modified state
MESI/MOESI Coherence
MSI and MOSI coherence can be optimized for thread-private data by introducing an exclusive state, hence MESI/MOESI Coherence.
When a block is read and the cache detects that it’s the only copy of that block in all of the caches, it transitions from the invalid state to the exclusive state. It can then transition straight to the modified state on a write.
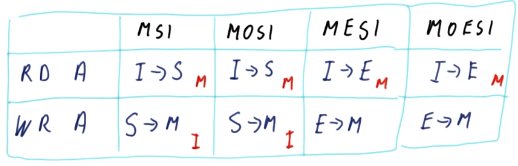
If a block is in the exclusive state and it’s written to, it transitions to the modified state.
If a block is in the exclusive state and it snoops a read, then it’s no longer the only copy of that block in all of the caches, so it transitions to the shared state.
Directory-based Coherence
Directory-based coherence is a coherence policy that recognizes that the bus can be a bottleneck when there is a large number of cores (e.g. 8-16 cores). A directory is a structure that is distributed across all cores so that each core gets a slice of the directory which serves a set of blocks 2.
The directory has one entry for each block it serves which tracks which caches have that block. Specifically it contains a dirty bit specifying whether the block is dirty in some cache and 1 bit for each cache denoting that the block is in that cache, i.e. a bitmap index.
Directory-based coherence essentially works by having an index (the directory) that is address-range-based partitioned among each core. All requests go to the partition (a home slice) that manages a block address. The index entry is itself another index (a bitmap) specifying which caches contain the block (if any) and if the block may be dirty. The entry is updated to reflect any MESI/MOESI state transitions.
Synchronization
An atomic exchange instruction is an instruction that atomically swaps the data in the operands.
Load Linked/Store Conditional (LL/SC) instructions are a pair of instructions that work together. The Load Linked (LL) instruction is like any other instruction but it saves the address it loaded into a link register. The Store Conditional (SC) instruction checks if the address of its destination is the same as the one in the link register. If so, it does a normal store and returns 1, otherwise if returns 0. This ensures atomicity by relying on coherence to zero out the link register based on the operand to link load.
LL r1, lockvar
SC r2, lockvar
Atomic reads/writes in the same instruction are bad for pipelining because it requires multiple memory stages in the pipelining in order to perform both the read and the write instead of just one of those.
Single-variable atomic operations can be implemented in terms of load linked/store conditional (LL/SC) by surrounding the operation with LL/SC, then checking the return value of SC to determine if the operation was not interrupted. If it was, the operation is retried until success. For example, atomic increment:
try:
LL r1, var
r1++
sc r1, var
if (r1 == 0) goto try
Implementing a spinlock with an unconditional atomic exchange is bad because the cores that are spinning on the lock continuously perform unconditional yet inconsequential writes. The writes generate a lot of coherence traffic on the bus, using up a lot of power and closing down cache misses further on the processor doing the actual work.
A way of improving an atomic exchange implementation of a spinlock is to preced the atomic exchange with another busy loop on the lock variable, so that the exchange is only attempted once the lock variable is observed to be free. This leverages cache hits and cache coherence:
res = 1;
while (res == 1) {
while (lockvar == 1) {}
EXCH r1, lockvar
}
A barrier can be implemented with a counter variable that counts arriving threads and ready flag that is set when all threads have arrived. The ready flag is set to a thread-local value which starts the same and alternates independently each time it enters a new barrier, in order to ensure that the barrier is reusable.

Memory Consistency
The order of accesses to the same address is defined by coherence.
The order of accesses to different addresses is defined by memory consistency.
Sequential memory consistency means that the accesses from one core are not reordered, but there could be many possible interleavings of accesses from different cores.
A possible implementation of sequential consistency would have to ensure that a core performs the next access only when all previous accesses are complete, which would mean poor performance.
It would be better if it re-orders a sequence of loads. So for example, load $A$ and load $B$ gets re-ordered to load $B$ and load $A$, then the coherence traffic must be monitored to see if a write to $B$ occurs before load $A$ is executed, in which case the previous load $B$ must be replayed.
The four kinds of memory access orderings are:
- write A, write B
- write A, read B
- read A, write B
- read A, read B
Unlike sequential consistency where all orderings must be enforced, a relaxed consistency model allows certain kinds of memory accesses to not be enforced. For example, “read A, read B” accesses can be made out-of-order.
In a system with a relaxed consistency model, ordering constraints are enforced on memory accesses via special instructions, memory barriers, which ensure that previous memory accesses are complete before proceeding.
A memory barrier (aka fence) is an instruction in a system with a relaxed consistency model that ensures that all memory access instructions (of a certain kind) prior to the barrier (in program order) are complete before proceeding. For example, msync on x86.
The volatile keyword in C/C++ ensures that reads and writes are not reordered by the compiler via instruction scheduling. It has no effect on memory consistency. Reads and writes to volatile variables do not guarantee a memory barrier. This means that volatile alone is not sufficient to use a variable for inter-thread communication.
A data race can occur when:
- one core reads and another writes to the same variable
- one core writes and another reads to the same variable
- one core writes and another writes to the same variable
A data-race-free program is one that runs the same as it would with sequential consistency in any other consistency model.
To facilitate debugging data-races in programs, some processors allow enabling sequential consistency on demand, such as while debugging.
Weak memory consistency distinguishes between synchronization and non-synchronization accesses. Synchronization accesses aren’t reordered among themselves or with other accesses (i.e. they’re sequentially-consistent). Non-synchronization accesses made between synchronization accesses can be reordered.
Release consistency distinguishes between acquires and releases, and they’re not reordered among themselves. Non-synchronization accesses can be reordered except that writes must complete before the next release synchronization (i.e. writes cannot be reordered/moved to after the next release) and reads cannot execute before the preceding acquire event (i.e. reads cannot be reordered/moved to before the previous acquire).
Sequential consistency can be achieved with weak consistency by treating every regular access as a synchronization access.
Release consistency can be achieved with weak consistency by treating every synchronization event as both an acquire and a release.
-
I wonder if this kind of prefetcher is meant for, for example, if someone iterates through a 2D array the “wrong” way, in column-major order, so first the first column of the first row, then the first column of the second row, and so on. Then a good stride prefetcher might recognize this access pattern and prefetch the appropriate column stripes. Though hopefully this would be recognized much sooner by the compiler and resolved with loop interchange. ↩︎
-
This is one of the many areas of computer architecture that reminds me of distributed systems. This is like partitioning data. ↩︎